P2P Network
This part outlines the BitcoinEvo P2P network protocol (though it is not official specification). It does not cover the now-discontinued direct IP-to-IP payment protocol, the obsolete BIP70 payment protocol, the GetBlockTemplate mining protocol, or any network protocols that were never incorporated into a recognized version of BitcoinEvo Core.All peer-to-peer communication takes place exclusively over TCP.
Note: Unless otherwise indicated, all multi-byte integers referenced in this section are sent in little-endian format.
Constants And Defaults
The following constants and defaults are derived from the BitcoinEvo Core’s chainparams.cpp source file.| Network | Default Port | Start String | Max nBits |
|---|---|---|---|
| Mainnet | 7333 | 0xefb4aacf | 0x1d00ffff |
| Testnet | 17333 | 0x0107fffd | 0x1d00ffff |
| Regtest | 17444 | 0xf0b5abd0 | 0x207fffff |
Note: The testnet start string and nBits provided refer to testnet3; the original testnet used different values for both the string and nBits (less difficult).
Command line parameters can modify the port a node uses (see -help). Start strings are pre-defined constants that are present at the beginning of all messages transmitted on the BitcoinEvo network; they may also be found in data files such as BitcoinEvo Core’s block database. The nBits displayed above are shown in big-endian format, but they are transmitted over the network in little-endian format.
BitcoinEvo Core’s chainparams.cpp file also contains other constants beneficial to programs, including the hash of the genesis blocks for different networks.
Protocol Versions
The table below highlights some important versions of the P2P network protocol, with the latest versions listed at the top.Message Headers
All messages in the protocol use a common container format, which includes a required multi-field message header and an optional data payload. The message header format is as follows:The example below is a labeled hex dump of a mainnet message header from a “verack” message, which contains no payload.
efb4aacf ................... Start string: Mainnet
76657261636b000000000000 ... Command name: verack + null padding
00000000 ................... Byte count: 0
5df6e0e2 ................... Checksum: SHA256(SHA256(<empty>))
Data Messages
The following messages in the network either request or supply data related to transactions and blocks.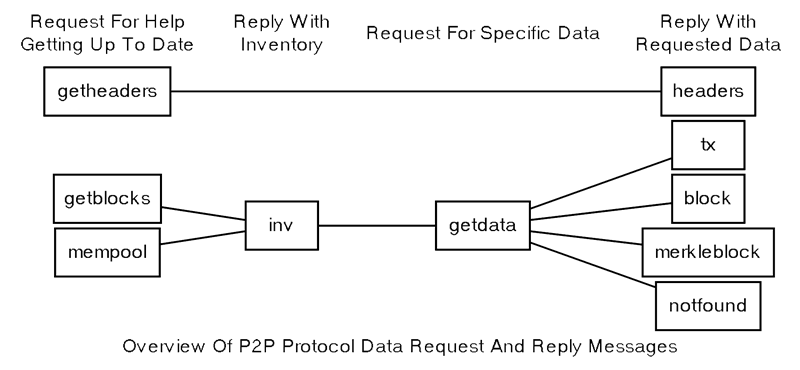
Overview Of P2P Protocol Data Request And Reply Messages
| Bytes | Name | Data Type | Description |
|---|---|---|---|
| 4 | type identifier | uint32_t | Represents the type of object that was hashed. See the list of type identifiers below. |
| 32 | hash | char[32] | SHA256(SHA256()) hash of the object, presented in internal byte order. |
The available type identifiers currently include:
| Type Identifier | Name | Description |
|---|---|---|
| 1 | “MSG_TX” | The hash is a TXID (transaction identifier). |
| 2 | “MSG_BLOCK” | The hash represents a block header. |
| 3 | “MSG_FILTERED_BLOCK” | The hash refers to a block header (same as “MSG_BLOCK”). When utilized in a “getdata” message, it indicates that the response should be a “merkleblock” message instead of a “block” message. This only functions if a bloom filter has been set up previously. It is only relevant for “getdata” messages. |
| 4 | “MSG_CMPCT_BLOCK” | The hash refers to a block header (same as “MSG_BLOCK”). When used in a “getdata” message, this specifies that the response should be a “cmpctblock” message. This is only valid in “getdata” messages. |
| 1† | “MSG_WITNESS_TX” | The hash is a TXID. In “getdata” messages, it indicates that the response should be a transaction message. If the witness structure exists, witness serialization will be employed. It is only for use in “getdata” messages. |
| 2† | “MSG_WITNESS_BLOCK” | The hash points to a block header (same as “MSG_BLOCK”). In “getdata” messages, it signals that the response should be a block message containing transactions with a witness structure using witness serialization. It is only for use in “getdata” messages. |
| 3† | “MSG_FILTERED_WITNESS_BLOCK” | Reserved for future implementations, currently unused as of Protocol Version 70015. |
† These identifiers are identical to their respective types but with the 30th bit set to denote witness. For example, MSG_WITNESS_TX = 0x01000040.
Type identifier zero and any identifiers greater than seven are reserved for future versions. BitcoinEvo Core ignores all inventories with an unrecognized type.
Block
The “block” message is used to send a single serialized block, as described in the serialized blocks section. Refer to that section for an example hexdump. This message can be sent for two reasons:- GetData Response: Nodes will send it in reply to a “getdata” message requesting a block with the inventory type “MSG_BLOCK” (as long as the node possesses the block for relay).
- Unsolicited: Some miners send “block” messages without requests, broadcasting newly-mined blocks to all their connected peers. Many mining pools follow this practice, although certain pools may be improperly configured and end up sending the block from multiple nodes, potentially delivering the same block to some peers multiple times.
GetBlocks
The “getblocks” message is used to request an “inv” message that lists block header hashes starting from a specified point in the blockchain. This is helpful for a peer that has either been disconnected or is syncing for the first time, allowing it to identify the blocks it needs to download.Peers that have been disconnected may have outdated blocks stored in their local blockchain, so the “getblocks” message lets the requesting peer supply the receiving peer with multiple header hashes at different points along its local chain. The receiving peer can then identify the last common header and send all the subsequent block header hashes.
Note: The receiving peer might respond with an “inv” message containing header hashes of obsolete blocks. It is up to the requesting peer to check all peers and determine the best blockchain.
If the receiving peer is unable to find a common header hash within the provided list, it will assume the last common block was the genesis block (block zero), and reply with an “inv” message starting from block one (the block immediately following the genesis block).
The following annotated hexdump shows a “getblocks” message. (The message header has been omitted.)
71110100 ........................... Protocol version: 70001
02 ................................. Hash count: 2
d39f608a7775b537729884d4e6633bb2
105e55a16a14d31b0000000000000000 ... Hash #1
5c3e6403d40837110a2e8afb602b1c01
714bda7ce23bea0a0000000000000000 ... Hash #2
00000000000000000000000000000000
00000000000000000000000000000000 ... Stop hash
GetData
The “getdata” message is used to request one or more specific data objects from another node. These objects are identified by an inventory, which the requesting node typically received earlier via an “inv” message.The response to a “getdata” message can be a “tx” message, “block” message, “merkleblock” message, “cmpctblock” message, or in some cases, a “notfound” message.
This message cannot be used to ask for arbitrary data, such as old transactions no longer in the memory pool or relay set. Full nodes may not even have access to older blocks if they’ve pruned old transactions from their block databases. For this reason, the “getdata” message should generally only be used to request data that a node had previously advertised as available by sending an “inv” message.
The structure and size limits of the “getdata” message are the same as for the “inv” message; only the message header differs.
GetHeaders
The “getheaders” message requests a “headers” message containing block headers starting from a specific point in the blockchain. This allows a peer that has been disconnected or is starting for the first time to obtain the headers it has not yet received.The “getheaders” message is almost the same as the “getblocks” message, with one key difference: the inv response to a “getblocks” message will contain no more than 500 block header hashes, while the headers response to a “getheaders” message can include up to 2,000 block headers.
Headers
The “headers” message provides block headers to a node that has previously requested specific headers using a “getheaders” message. A headers message can sometimes be empty.| Bytes | Name | Data Type | Description |
|---|---|---|---|
| Varies | count | compactSize uint | Number of block headers, up to a maximum of 2,000. Note: during headers-first synchronization, the sending node should send the maximum number of headers whenever possible. |
| Varies | headers | block_header | Block headers: each 80-byte block header follows the format explained in the block headers section with an additional 0x00 at the end. This 0x00 represents the transaction count, but since the headers message doesn’t include any transactions, the count is always zero. |
The following annotated hexdump shows a “headers” message. (The message header has been excluded.)
01 ................................. Header count: 1
02000000 ........................... Block version: 2
b6ff0b1b1680a2862a30ca44d346d9e8
910d334beb48ca0c0000000000000000 ... Hash of previous block's header
9d10aa52ee949386ca9385695f04ede2
70dda20810decd12bc9b048aaab31471 ... Merkle root
24d95a54 ........................... [Unix time][unix epoch time]: 1415239972
30c31b18 ........................... Target (bits)
fe9f0864 ........................... Nonce
00 ................................. Transaction count (0x00)
Inv
The “inv” message (inventory message) communicates one or more inventories of objects known to the transmitting peer. It can be sent unsolicited to announce new transactions or blocks, or as a reply to a “getblocks” message or “mempool” message.The receiving peer can compare the inventories received from an “inv” message against its own list of seen inventories and send a follow-up request for any objects it hasn’t yet encountered.
| Bytes | Name | Data Type | Description |
|---|---|---|---|
| Varies | count | compactSize uint | The total number of inventory entries. |
| Varies | inventory | inventory | One or more inventory entries, up to a maximum of 50,000. |
The following annotated hexdump shows an “inv” message containing two inventory entries. (The message header has been omitted.)
02 ................................. Count: 2
01000000 ........................... Type: MSG_TX
de55ffd709ac1f5dc509a0925d0b1fc4
42ca034f224732e429081da1b621f55a ... Hash (TXID)
01000000 ........................... Type: MSG_TX
91d36d997037e08018262978766f24b8
a055aaf1d872e94ae85e9817b2c68dc7 ... Hash (TXID)
MemPool
The “mempool” message requests the TXIDs of transactions that the receiving node has validated as legitimate but have not yet been included in a block. In other words, it retrieves the transactions currently residing in the receiving node’s memory pool. The response to the “mempool” message will be one or more “inv” messages containing these TXIDs in the usual inventory format.Sending the “mempool” message is mainly useful when a program first joins the network. Full nodes can use it to quickly collect most or all of the unconfirmed transactions circulating on the network. This is particularly beneficial for miners who are trying to gather transactions to include for fee collection. SPV clients may set a filter before sending a mempool request to limit the response to transactions that match the filter criteria. This allows a newly-started client to gather most or all unconfirmed transactions relevant to its wallet.
However, the inv response to a “mempool” message is only a single node’s perspective on the network — not a comprehensive list of all unconfirmed transactions. Here are some reasons the response might not be complete:
- Before BitcoinEvo Core, the response to a “mempool” message consisted of just one “inv” message. Since an “inv” message can only carry up to 50,000 inventories, a node with a memory pool larger than 50,000 entries would not send all of them. Newer versions of BitcoinEvo Core will send as many “inv” messages as required to cover their entire memory pool.
- The “mempool” message doesn’t fully support the “filterload” message’s BLOOM_UPDATE_ALL and BLOOM_UPDATE_P2PUBKEY_ONLY flags. Since mempool transactions aren’t ordered like in-block transactions, a transaction spending an output might appear before the transaction containing that output, causing the automatic filter update mechanism to miss the earlier transaction. It’s been suggested that transactions should be sorted before being processed by the filter.
MerkleBlock
The “merkleblock” message is a response to a “getdata” message requesting a block using the MSG_MERKLEBLOCK inventory type. This message is only part of the response: if any matching transactions are found, they will be sent as separate “tx” messages.If a filter was previously set using the “filterload” message, the “merkleblock” message will include the TXIDs of any transactions in the requested block that matched the filter, along with the necessary portions of the block’s merkle tree to link those transactions to the block header’s merkle root. This message also contains a complete copy of the block header, which allows the client to hash it and verify its proof of work.
| Bytes | Name | Data Type | Description |
|---|---|---|---|
| 80 | block header | block_header | The block header, formatted as described in the block header section. |
| 4 | transaction count | uint32_t | The number of transactions in the block (including those not matching the filter). |
| Varies | hash count | compactSize uint | The total number of hashes in the subsequent field. |
| Varies | hashes | char[32] | One or more 32-byte hashes of both transactions and merkle nodes in internal byte order. |
| Varies | flag byte count | compactSize uint | The number of flag bytes in the subsequent field. |
| Varies | flags | byte[] | A sequence of bits packed into bytes (LSB first). Padded to byte boundaries but must not contain extra bits. Used to map hashes to specific nodes in the merkle tree as described below. |
The following annotated hexdump shows a “merkleblock” message corresponding to the examples below. (The message header has been omitted.)
01000000 ........................... Block version: 1
82bb869cf3a793432a66e826e05a6fc3
7469f8efb7421dc88067010000000000 ... Hash of previous block's header
7f16c5962e8bd963659c793ce370d95f
093bc7e367117b3c30c1f8fdd0d97287 ... Merkle root
76381b4d ........................... Time: 1293629558
4c86041b ........................... nBits: 0x04864c * 256**(0x1b-3)
554b8529 ........................... Nonce
07000000 ........................... Transaction count: 7
04 ................................. Hash count: 4
3612262624047ee87660be1a707519a4
43b1c1ce3d248cbfc6c15870f6c5daa2 ... Hash #1
019f5b01d4195ecbc9398fbf3c3b1fa9
bb3183301d7a1fb3bd174fcfa40a2b65 ... Hash #2
41ed70551dd7e841883ab8f0b16bf041
76b7d1480e4f0af9f3d4c3595768d068 ... Hash #3
20d2a7bc994987302e5b1ac80fc425fe
25f8b63169ea78e68fbaaefa59379bbf ... Hash #4
01 ................................. Flag bytes: 1
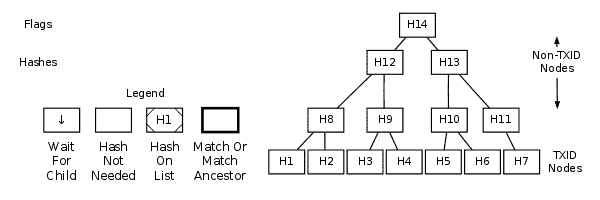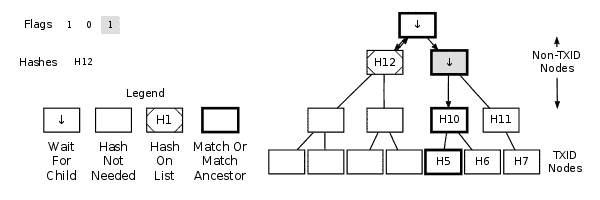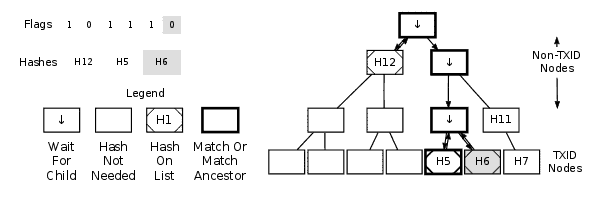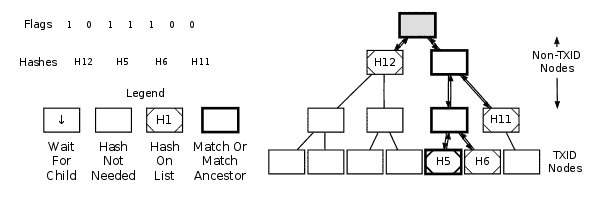
1d ................................. Flags: 1 0 1 1 1 0 0 0
Note: When fully decoded, the above “merkleblock” message provided the TXID for a single transaction that matched the filter. In the network traffic capture this output was taken from, the full transaction for that TXID was sent immediately after the “merkleblock” message in a “tx” message.
Parsing A MerkleBlock Message
As seen in the annotated hexdump above, the “merkleblock” message introduces three key data types: a transaction count, a set of hashes, and a series of one-bit flags.You can utilize the transaction count to build an empty merkle tree. Each item in this tree is referred to as a node. At the bottom, there are TXID nodes — the hashes in these nodes are TXIDs. The remaining nodes (including the merkle root) are non-TXID nodes. Although some non-TXID nodes may contain the same hash as a TXID, they are treated as distinct.
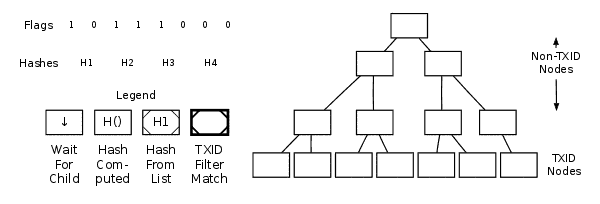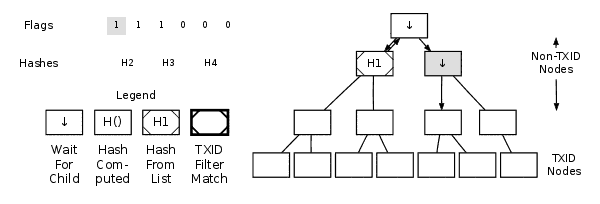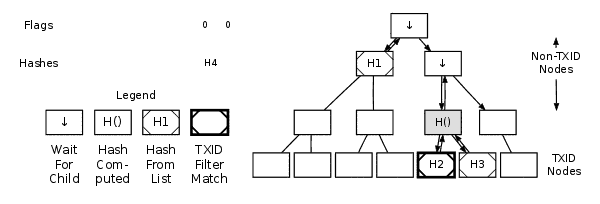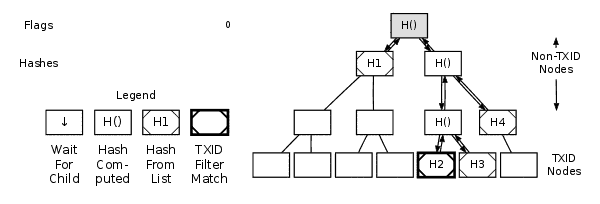
Example Of Parsing A MerkleBlock Message
Start at the merkle root node and evaluate the first flag. The table below outlines how to interpret a flag based on whether the current node is a TXID node or a non-TXID node. Once a flag has been applied to a node, that flag cannot be reused on the same node or reapplied.
| Flag | TXID Node | Non-TXID Node |
|---|---|---|
| 0 | Use the next hash as this node’s TXID, but the transaction didn’t match the filter. | Use the next hash as this node’s value. Don’t process any descendant nodes. |
| 1 | Use the next hash as this node’s TXID and mark the transaction as matching the filter. | Compute the hash by processing the left and right child nodes, concatenating their hashes, and hashing the result to get this node’s value. |
Each time you begin processing a new node, evaluate the next flag. Flags should never be reused at any other stage.
When you process a child node, you may need to handle its own children (i.e., the grandchildren of the current node) or nodes further down the hierarchy before returning to the parent node. This is normal — continue using a depth-first approach until you hit a TXID node or a non-TXID node with a flag of 0.
Once you process a TXID node or a non-TXID node with a flag of 0, stop handling flags and start moving back up the tree. As you move up, compute the hashes for any nodes where both child hashes are now available or for nodes with only one known child hash. Refer to the merkle tree section for hashing instructions. If you encounter a node where only the left child’s hash is known, descend into its right child (if it exists) and continue descending as needed.
However, if a node’s left and right children share the same hash, an error occurs.
Continue alternating between descending and ascending until you have enough data to compute the merkle root node’s hash. If you run out of hashes or flags before reaching this point, the process fails. Perform these checks afterward (in any order):
- Fail if there are unused hashes remaining in the list.
- Fail if there are any unprocessed flag bits, except for the minimum required to pad the list to the next byte boundary.
- Fail if the calculated merkle root hash does not match the merkle root in the block header.
- Fail if the block header is invalid. Ensure that the block header’s hash is less than or equal to the target encoded by the nBits field in the header. Your program should also verify that the block belongs to the best chain and that the user is informed of how many confirmations the block has.
Creating A MerkleBlock Message
Understanding how to create a “merkleblock” message becomes easier once you’ve learned how to parse an existing message, so it’s advised to read the parsing section above first.Construct a complete merkle tree with TXIDs at the bottom row and compute the remaining hashes up to the merkle root at the top. For every transaction that matches the filter, keep track of its TXID node and all its ancestor nodes.
Example Of Creating A MerkleBlock Message
| TXID Node | Non-TXID Node | |
|---|---|---|
| Neither Match Nor Match Ancestor | Append a 0 to the flag list; append this node’s TXID to the hash list. | Append a 0 to the flag list; append this node’s hash to the hash list. Do not descend into its child nodes. |
| Match Or Match Ancestor | Append a 1 to the flag list; append this node’s TXID to the hash list. | Append a 1 to the flag list; process the left child node. Then, if the node has a right child, process the right child. Do not append a hash to the hash list for this node. |
Each time you begin handling a new node, a flag should be appended to the flag list. You should not append flags at any other point except when the process is finished, to pad the list to the nearest byte boundary.
When processing a child node, you may need to handle its descendants (grandchildren of the initial node) before moving back to the parent node. This is expected — continue with depth-first processing until you hit a TXID node or a node that’s neither a TXID nor a match ancestor.
After processing a TXID node or a node that’s neither a TXID nor a match ancestor, stop processing and move back up the tree until you reach a node with an unprocessed right child. Descend into that right child and handle it.
After completely processing the merkle root node according to the instructions above, you’re done. Pad the flag list to the next byte boundary, and then construct the “merkleblock” message using the template from earlier in this section.
CmpctBlock
Version 1 compact blocks are for pre-SegWit (txids), while Version 2 compact blocks are for post-SegWit (wtxids).The “cmpctblock” message is sent as a response to a “getdata” message that requested a block using the inventory type “MSG_CMPCT_BLOCK”. If the block requested has been recently announced and is near the tip of the receiver’s best chain — and after the requesting peer has received a “sendcmpct” message — nodes will respond with a “cmpctblock” message containing block data.
However, if the block in question is too old, the node will respond with a full, non-compact block.
After receipt a “cmpctblock” message, and after sending a “sendcmpct” message, nodes should compute the short transaction ID for each unconfirmed transaction they currently hold in their mempool. They should then compare each to the short transaction IDs included in the “cmpctblock” message. If some transactions are already available, nodes should request any missing transactions using a “getblocktxn” message if they can’t fully reconstruct the block.
A node should not send a “cmpctblock” message unless it can also respond to a “getblocktxn” message requesting every transaction in the block. Furthermore, a node must verify that the block header commits properly to every transaction in the block and that it is correctly building on the current valid chain with proof-of-work. It should either be part of the current chain with the most work or directly building on top of it. A node may send a “cmpctblock” message before verifying that each transaction correctly spends existing UTXO set entries.
The “cmpctblock” message contains a vector of “PrefilledTransaction,” whose structure is outlined below.
| Bytes | Name | Data Type | Description |
|---|---|---|---|
| Varies | index | compactSize uint | The index in the block where this transaction is located. |
| Varies | tx | Transaction | The transaction that is located at the given index in the block. |
The “cmpctblock” message consists of a serialized “HeaderAndShortIDs” structure, defined below. This structure is used to send the block header, short transaction IDs for matching already-known transactions, and a few transactions that the peer may be missing.
Important Protocol Version 70015 Notes for Compact Blocks
In protocol version 70015, new banning behavior was added to the compact block logic to prevent abuse, as outlined in BIP152.
Undefined behavior in this specification may result in block transfer failures, peer disconnections, or crashes for the receiving node. A node that encounters non-minimally-encoded CompactSize values should make every effort to penalize the sender appropriately.
Since high-bandwidth mode allows “cmpctblock” messages to be relayed before full validation (requiring only the validation of the block header before relaying), nodes should not ban peers for announcing a new block with a “cmpctblock” message that turns out to be invalid, as long as the header is valid.
To clarify, nodes should update their peer-to-peer protocol version to 70015 or higher to indicate that they will not ban peers for sending compact blocks before full validation. Nodes should also avoid announcing a “cmpctblock” message to peers with protocol versions below 70015 until they have fully validated the block.
Version 2 Compact Blocks Notes
Transactions in “cmpctblock” messages (whether used for direct announcement or in response to “getdata”) and in “blocktxn” messages must include witness data, using the format specified in BIP144 for responses to “getdata” with “MSG_WITNESS_TX”.
If a node receipt a “getdata” message requesting a “MSG_CMPCT_BLOCK” object but does not send a “cmpctblock” message in response, it must send the block message in non-compact form with witness data if the block is encoded using Version 2 (as for “MSG_WITNESS_BLOCK”) and without witness data if encoded using Version 1 (as for “MSG_BLOCK”).
Short Transaction ID Calculation
Short transaction IDs are used to represent transactions without transmitting the complete 256-bit hash. They are computed using the following steps:
- Perform a single SHA-256 hash of the block header, with the nonce appended in little-endian format.
- Apply SipHash-2-4, using the transaction ID as the input (or wtxid for Version 2 compact blocks). The keys (k0/k1) are derived from the first two little-endian 64-bit integers of the previously calculated hash.
- Remove the 2 most significant bytes from the SipHash output, reducing the result to 6 bytes.
- Finally, append two null bytes to allow the result to be interpreted as an 8-byte integer.
SendCmpct
The “sendcmpct” message consists of a 1-byte integer followed by an 8-byte integer. The first integer is treated as a boolean, with a value of either 1 or 0, while the second integer is interpreted as a little-endian version number.When a node receipt a “sendcmpct” message where both integers are set to 1, it should begin announcing new blocks using the “cmpctblock” message format.
If the “sendcmpct” message has the first integer set to 0, the node should not use “cmpctblock” messages for announcing new blocks. Instead, the node should announce blocks using inventory messages (invs) or headers, as outlined in BIP130.
When the second integer in the “sendcmpct” message is anything other than 1, nodes should treat the peer as if the message was not receipt. This is because the different value signals that the peer may use an unexpected encoding in the “cmpctblock” messages or other communication. This approach also enables future protocol versions to send multiple “sendcmpct” messages with varying versions as part of a version negotiation process.
Nodes must verify the protocol version before sending or responding to “sendcmpct” messages. Nodes should not request a “MSG_CMPCT_BLOCK” object from a peer without first receiving a “sendcmpct” message from that peer. Similarly, nodes should avoid sending a “MSG_CMPCT_BLOCK” request until all intended “sendcmpct” messages have been sent, so the peer knows which version protocol to use for its response.
The structure of the “sendcmpct” message is outlined below:
| Bytes | Name | Data Type | Description |
|---|---|---|---|
| 1 | announce | bool | An integer representing a boolean value: 0x01 (true) or 0x00 (false). |
| 8 | version | uint64_t | A little-endian version number. Set to 2 for Version 2 compact blocks. |
GetBlockTxn
The “getblocktxn” message consists of a serialized “BlockTransactionsRequest” message. When a node receipt a properly formatted “getblocktxn” message, and if it has recently sent a “cmpctblock” message for the block hash identified in the request, it must reply with either a “blocktxn” message or a full block.The “blocktxn” message response must only contain the transactions that correspond to the indexes provided in the “getblocktxn” message, in the order requested.
The structure of the “BlockTransactionsRequest” is described below.
BlockTxn
Described in BIP152.The “blocktxn” message is a message that includes a serialized “BlockTransactions” message. Upon receiving a valid “blocktxn” message in response to a request, nodes should attempt to reconstruct the full block by combining the prefilled transactions from the initial “cmpctblock” message with the newly received transactions. These transactions should be placed in the designated positions, and any remaining short transaction IDs from the “cmpctblock” message should be filled in order, using either transactions from the “blocktxn” message or other sources. Once the full block has been reconstructed, the node processes it normally, keeping in mind that short transaction IDs may occasionally collide. Nodes must not penalize peers for these collisions.
The structure of the “BlockTransactions” message is as follows:
| Bytes | Name | Data Type | Description |
|---|---|---|---|
| 32 | block hash | binary blob | The block hash of the block that contains the provided transactions. |
| Varies | transactions length | compactSize uint | The total number of transactions included. |
| Varies | transactions | Transactions[] | A vector of transactions. For an example of the raw transaction format, refer to the raw transaction section. |
NotFound
The “notfound” message is a response to a “getdata” message when the requested object is not available for relay by the receiving node. Nodes are not required to relay historical transactions that are no longer in their memory pool or relay set. Additionally, nodes may have pruned old transactions from blocks, preventing them from sending those blocks.The structure and size constraints of the “notfound” message are identical to those of the “inv” message, differing only in the message header.
Tx
The “tx” message transmits a single transaction in its raw format. It can be sent under various circumstances:- Transaction Response: BitcoinEvo Core and BitcoinEvoJ will send it in response to a “getdata” message that requests a transaction with the inventory type “MSG_TX”.
- MerkleBlock Response: BitcoinEvo Core sends it as part of a response to a “getdata” message requesting a merkle block with the inventory type MSG_MERKLEBLOCK. This is sent alongside a “merkleblock” message, and each “tx” message provides a matched transaction from that block.
- Unsolicited: BitcoinEvoJ will also send a “tx” message without any request for transactions that it originates.<
Control Messages
The following network messages help manage the connection between peers or provide advisory information about the network.
Overview Of P2P Protocol Control And Advisory Messages
Addr
The addr (address) message transmits connection information about peers on the network. A peer that is open to accepting incoming connections generates an “addr” or “addrv2” message with its connection details and sends this message unsolicited to its peers. Some of these peers may forward the information to their own peers, enabling decentralized peer discovery throughout the network.An “addr” message can also be sent in response to a “getaddr” message.
Each network IP address in the message follows the structure below:
The annotated hexdump below shows part of an “addr” message. (The message header is omitted, and the actual IP address has been replaced with a reserved IP address from RFC5737.)
fde803 ............................. Address count: 1000
d91f4854 ........................... [Unix time][epoch time]: 1414012889
0100000000000000 ................... Service bits: 01 (node)
00000000000000000000ffffc0000233 ... IP Address: ::ffff:192.0.2.51
208d ............................... Port: 7333
[...] .............................. (999 more addresses omitted)
Addrv2
The addrv2 (address version two) message relays peer connection information similar to the “addr” message, but it utilizes a different encoding method to support addresses longer than 16 bytes.Each address in the message uses the following structure (addrv2 encoding):
The annotated hexdump below shows a portion of an “addrv2” message (the message header has been omitted):
fde803 ............................. Address count: 1000
d91f4854 ........................... [Unix time][epoch time]: 1414012889
fd4804 ............................. Service bits: compactSize(NODE_WITNESS | NODE_COMPACT_FILTERS | NODE_NETWORK_LIMITED)
01 ................................. BIP155 network id: IPv4
04 ................................. Address length: compactSize(4)
c0000233 ........................... Address: 192.0.2.51
208d ............................... Port: 7333
[...] .............................. (999 more addresses omitted)
Alert
The legacy P2P alert messaging system has been retired, although internal alerts, partition detection warnings, and the-alertnotify feature remain active.
FeeFilter
The “feefilter” message is a request sent to the receiving peer, asking it not to relay any transaction inventory messages (inv) where the fee rate is below the threshold specified in the “feefilter” message.The feefilter feature was introduced following the implementation of mempool limiting in BitcoinEvo Core, aimed at preventing spam and low-fee transactions from overwhelming the network. By using “feefilter” messages, a node can instruct its peers not to relay transactions that fall below a specified fee rate, thus allowing the peer to avoid adding such transactions to its mempool.
| Bytes | Name | Data Type | Description |
|---|---|---|---|
| 8 | feerate | uint64_t | The fee rate (in satoshis per kilobyte) below which transactions should not be relayed. |
The receiving peer may choose to ignore the “feefilter” message and continue to relay transactions.
The fee filter works in combination with bloom filters. If a lightweight client (SPV) sets a bloom filter and sends a feefilter message, transactions will only be relayed if they pass both filters.
Note that the “feefilter” does not affect block propagation or responses to “getdata” messages. For instance, if a node requests a merkle block using “getdata” with inv type “MSG_FILTERED_BLOCK” and has sent a “feefilter” message earlier, the peer should still send the merkleblock containing all transactions matching the bloom filter, even if they have lower fees than the filter’s threshold.
Inv messages triggered by a mempool message are also subject to the fee filter if it is in place.
The following annotated hexdump illustrates a “feefilter” message (message header omitted):
7cbd000000000000 ... satoshis per kilobyte: 48,508
FilterAdd
The “filteradd” message tells the receiving peer to add a specific element, like a public key, to an existing bloom filter. The element is sent directly to the peer, which will then use the parameters from the previously-sent “filterload” message to integrate the element into the filter.Since the element is transmitted without any obfuscation, there is no privacy protection as provided by bloom filters. Clients aiming to maintain higher privacy should manually recalculate the bloom filter and send a fresh “filterload” message containing the recalculated filter.
| Bytes | Name | Data Type | Description |
|---|---|---|---|
| Varies | element bytes | compactSize uint | The number of bytes in the following element field. |
| Varies | element | uint8_t[] | The element to add to the current filter. Maximum size is 520 bytes, and the element must appear in the byte order used in raw transactions (e.g., hashes in internal byte order). |
Note: A “filteradd” message will only be accepted if a bloom filter was previously set using a “filterload” message.
The annotated hexdump below shows a “filteradd” message adding a TXID (the message header has been omitted). After sending this “filteradd” message, if the same “merkleblock” message is re-sent, six hashes will be returned instead of four:
20 ................................. Element bytes: 32
fdacf9b3eb077412e7a968d2e4f11b9a
9dee312d666187ed77ee7d26af16cb0b ... Element (A TXID)
FilterClear
The “filterclear” message instructs the receiving peer to remove any previously-set bloom filter. This action also reverses the effect of setting the relay field to 0 in the “version” message, thus re-enabling unfiltered access to “inv” messages that announce new transactions.BitcoinEvo Core does not require a “filterclear” message before loading a new filter using filterload. Similarly, a “filterclear” message can be sent even if no filter was previously set.
There is no payload in a “filterclear” message. For an example of a message without a payload, see the message header section.
FilterLoad
The “filterload” message instructs the receiving peer to apply a bloom filter to all relayed transactions and merkle block requests. This filter allows clients to receive transactions relevant to their wallet, along with a configurable false-positive rate that helps preserve plausible-deniability privacy.| Bytes | Name | Data Type | Description |
|---|---|---|---|
| Varies | nFilterBytes | compactSize uint | The size of the filter bit field in bytes. |
| Varies | filter | uint8_t[] | A byte-aligned bit field. The maximum size is 36,000 bytes. |
| 4 | nHashFuncs | uint32_t | The number of hash functions to apply to this filter (maximum: 50). |
| 4 | nTweak | uint32_t | A random seed added to the bloom filter’s hash function for uniqueness. |
| 1 | nFlags | uint8_t | Flags to control how outpoints related to a matching pubkey script are handled. |
The following annotated hexdump shows a “filterload” message (message header omitted). See the filterload example for details on how this payload was created.
02 .......... Filter bytes: 2
b50f ........ Filter: 1010 1101 1111 0000
0b000000 .... nHashFuncs: 11
00000000 .... nTweak: 0/none
00 .......... nFlags: BLOOM_UPDATE_NONE
Initializing A Bloom Filter
Bloom filters are configured based on two main parameters: the size of the bit field and the number of hash functions applied to each data element. The following BIP37 formulas help you choose suitable values based on the number of elements (n) you plan to add and the desired false positive rate (p) for maintaining plausible deniability.
- Bit field size in bytes (nFilterBytes), up to a maximum of 36,000 bytes:
(-1 / log(2)^2 * n * log(p)) / 8 - Number of hash functions (nHashFuncs), with a limit of 50:
nFilterBytes * 8 / n * log(2)
According to BIP37, these formulas allow bloom filters to support up to 20,000 items with a false positive rate of less than 0.1% or up to 10,000 items with a false positive rate below 0.0001%.
Once the bit field size is determined, it should be initialized with all zeroes. Populating A Bloom Filter
A bloom filter is populated using between 1 and 50 hash functions, with the number specified by the
nHashFuncs field. Instead of implementing up to 50 different hash functions, a single hash function is used, with each iteration employing a unique seed value.The seed is calculated as:
The seed is nHashNum * 0xfba4c795 + nTweak as a uint32_t, where the values are:
- nHashNum is the index of the hash function, starting at 0 for the first iteration and incrementing up to
nHashFuncs - 1for the final iteration. - 0xfba4c795 is a constant chosen to ensure significant variation in the seed values across different
nHashNumvalues. - nTweak is an arbitrary value set by the client to ensure unique seeds for each filter.
The actual hash function used is the 32-bit version of Murmur3.
Warning: Murmur3 has separate 32-bit and 64-bit versions, which produce different results for the same input. Only the 32-bit version is used in BitcoinEvo bloom filters.
The data to be hashed can be any transaction element that the bloom filter is designed to match. The largest element that can be matched is a 520-byte script data push, so data should never exceed this size.
The example from BitcoinEvo Core’s
bloom.cpp illustrates how to generate the hash template. The seed is the first parameter, and the data to be hashed is the second. The result is a uint32_t value modulo the size of the bit field (in bits).
MurmurHash3(nHashNum * 0xFBA4C795 + nTweak, vDataToHash) % (vData.size() * 8)
Each data element added to the filter is hashed by the number of functions specified by nHashFuncs. Each hash function generates an index number (nIndex), corresponding to a bit in the bit field. That bit is then set to 1. For example, if the filter’s bit field was initially 00000000 and the resulting nIndex is 5, the updated bit field would become 00000100 (with the first bit being 0).It’s normal for the same index to be generated multiple times during the population process, but this does not affect the algorithm. Once a bit is set to 1, it is never reset to 0.
After all elements have been added to the filter, each group of eight bits is converted into a little-endian byte, which then becomes the value of the filter field. Comparing Transaction Elements to a Bloom Filter
To compare an arbitrary data element against the bloom filter, it must be hashed using the same parameters used during the filter creation process. This means it will be hashed
nHashFuncs times, each time using the same nTweak value provided in the filter. The result of each hash is then taken modulo the size of the bit field defined in the filter. After each hash is computed, the bloom filter checks whether the bit at the resulting index is set. For example, if a hash result points to index 5, and the filter is 01001110, the bit at position 5 is considered set.If all hash results correspond to bits that are set, the filter matches. However, if any of the results corresponds to an unset bit, the filter does not match.
The following transaction elements are evaluated against bloom filters. All elements will be hashed in the same byte order as they appear in blocks (e.g., TXIDs are hashed in internal byte order).
- TXIDs: The SHA256(SHA256()) hash of the transaction.
- Outpoints: Each 36-byte outpoint used in the transaction’s input section is independently compared to the filter.
- Signature Script Data: Each data element pushed onto the stack by a data-pushing opcode in a signature script from this transaction is compared to the filter individually. This includes elements from P2SH redeem scripts when they are being spent.
- PubKey Script Data: Each element pushed onto the stack by any data-pushing opcode in a pubkey script is compared to the filter. If a pubkey script element matches the filter, the bloom filter will be immediately updated if the
BLOOM_UPDATE_ALLflag is set. Additionally, if the pubkey script is in the P2PKH format and matches the filter, the bloom filter will be updated if theBLOOM_UPDATE_P2PUBKEY_ONLYflag is set. (See the subsection below for further details.)
01000000017b1eab[…]“) would also be checked, and the outpoint TXID and index number would be compared as a single 36-byte element.01000000 ................................... Version
01 ......................................... Number of inputs
|
| 7b1eabe0209b1fe794124575ef807057
| c77ada2138ae4fa8d6c4de0398a14f3f ......... Outpoint TXID
| 00000000 ................................. Outpoint index number
|
| 49 ....................................... Bytes in sig. script: 73
| | 48 ..................................... Push 72 bytes as data
| | | 30450221008949f0cb400094ad2b5eb3
| | | 99d59d01c14d73d8fe6e96df1a7150de
| | | b388ab8935022079656090d7f6bac4c9
| | | a94e0aad311a4268e082a725f8aeae05
| | | 73fb12ff866a5f01 ..................... Secp256k1 signature
|
| ffffffff ................................. Sequence number: UINT32_MAX
01 ......................................... Number of outputs
| f0ca052a01000000 ......................... Satoshis (49.99990000 BTCE)
|
| 19 ....................................... Bytes in pubkey script: 25
| | 76 ..................................... OP_DUP
| | a9 ..................................... OP_HASH160
| | 14 ..................................... Push 20 bytes as data
| | | cbc20a7664f2f69e5355aa427045bc15
| | | e7c6c772 ............................. PubKey hash
| | 88 ..................................... OP_EQUALVERIFY
| | ac ..................................... OP_CHECKSIG
00000000 ................................... Locktime: 0 (a block height)
GetAddr
The “getaddr” message is used to request an “addr” or “addrv2” message from the receiving node, ideally containing a large number of addresses of other active nodes. This allows the transmitting node to quickly populate its database of available peers, rather than waiting for unsolicited “addr” or “addrv2” messages to gradually arrive.The “getaddr” message does not include any payload. For an example of a message without a payload, refer to the message header section.
Ping
The “ping” message is used to check whether the receiving peer is still actively connected. If there is an issue, such as a TCP/IP error or connection timeout while sending the “ping” message, the transmitting node can infer that the receiving node has disconnected. The appropriate response to a “ping” message is a “pong” message.In all versions, the message consists of a single field, which is a nonce.
The annotated hexdump below illustrates a “ping” message. (The message header is omitted.)
0094102111e2af4d ... NoncePong
The “pong” message is the response to a “ping” message, confirming that the node sending the “pong” is still operational. By default, BitcoinEvo Core will disconnect from clients that do not respond to a “ping” message within 20 minutes.To help track latency, the “pong” message returns the exact same nonce received in the corresponding “ping” message, allowing the pinging node to measure the round-trip time.
The structure of the “pong” message is identical to the “ping” message, with the only difference being in the message header.
Reject
The “reject” message is used to inform the receiving node that one of its previously sent messages has been declined.| Bytes | Name | Data Type | Description |
|---|---|---|---|
| Varies | message bytes | compactSize uint | Number of bytes in the following message field. |
| Varies | message | string | The type of message that was rejected, in ASCII text without null padding (e.g., “tx”, “block”, or “version”). |
| 1 | code | char | The reject message code (see the table below for details). |
| Varies | reason bytes | compactSize uint | Number of bytes in the following reason field. This may be 0x00 if no reason is provided. |
| Varies | reason | string | A textual explanation for the rejection in ASCII text (for debugging purposes only). |
| Varies | extra data | varies | Optional additional data associated with the rejection (e.g., the hash of the rejected transaction or block header). See the table below for details. |
The table below lists the various message reject codes, which are specific to the type of message they respond to. For instance, code 0x10 could be used for both transactions and blocks.
| Code | In Reply To | Extra Bytes | Extra Type | Description |
|---|---|---|---|---|
| 0x01 | any message | 0 | N/A | Message couldn’t be decoded. This can lead to “reject” message feedback loops where peers continuously send reject messages back and forth. |
| 0x10 | “block” | 32 | char[32] | The block is invalid (e.g., due to invalid proof-of-work, signatures, etc.). Extra data may include the hash of the rejected block’s header. |
| 0x10 | “tx” | 32 | char[32] | The transaction is invalid (e.g., invalid signatures, output greater than input, etc.). Extra data may include the rejected transaction’s TXID. |
| 0x11 | “block” | 32 | char[32] | The block uses an unsupported version. Extra data may include the rejected block’s header hash. |
| 0x11 | “version” | 0 | N/A | The connecting node is using an outdated protocol version that is not supported. |
| 0x12 | “tx” | 32 | char[32] | The transaction was rejected due to double spending (spending the same input twice). Extra data may include the rejected transaction’s TXID. |
| 0x12 | “version” | 0 | N/A | More than one “version” message was sent over this connection. |
| 0x40 | “tx” | 32 | char[32] | The transaction is considered non-standard by the node and will not be relayed or mined. Extra data may include the TXID of the rejected transaction. |
| 0x41 | “tx” | 32 | char[32] | One or more transaction outputs are below the dust threshold. Extra data may include the rejected transaction’s TXID. |
| 0x42 | “tx” | 32 | char[32] | The transaction was rejected due to an insufficient fee or priority. Extra data may include the rejected transaction’s TXID. |
| 0x43 | “block” | 32 | char[32] | The block is not part of the expected block chain (e.g., it belongs to a different chain). Extra data may include the rejected block’s header hash. |
Below is an annotated hexdump of a “reject” message (message header omitted):
02 ................................. Number of bytes in message: 2
7478 ............................... Type of message rejected: tx
12 ................................. Reject code: 0x12 (duplicate spend)
15 ................................. Number of bytes in reason: 21
6261642d74786e732d696e707574732d
7370656e74 ......................... Reason: bad-txns-inputs-spent
394715fcab51093be7bfca5a31005972
947baf86a31017939575fb2354222821 ... TXID
SendHeaders
The “sendheaders” message tells the receiving peer to send new block announcements using a “headers” message rather than an “inv” message.There is no payload in a “sendheaders” message. See the message header section for an example of a message without a payload.
SendAddrv2
The “sendaddrv2” message indicates that the sender is capable of understanding “addrv2” messages and prefers to receive them in place of the older “addr” messages.Like the “sendheaders” message, the “sendaddrv2” message has no payload. For an example of a message without a payload, see the message header section.
VerAck
The “verack” message serves as an acknowledgment of a previously received “version” message. It notifies the connecting node that it can now start sending other types of messages. The “verack” message carries no payload; for an example of such a message, refer to the message headers section.Version
The “version” message is used at the start of a connection to provide information about the transmitting node to the receiving node. Until both peers have exchanged “version” messages, no other types of messages will be processed.When a “version” message is accepted, the receiving node is expected to send a “verack” message in response. However, no node should send a “verack” message before initializing its own half of the connection by first sending its own “version” message.
The following service identifiers have been assigned.
Note: BitcoinEvo Core introduced an optional relay field, adding a potential extra byte to the “version” message. This results in an incompatibility with older protocol versions that strictly validate the size of the “version” message. When supporting protocol versions earlier than 70001, it’s essential to consider the possibility of a peer sending an extra byte and handle it accordingly. This extra byte should only be treated as invalid if the protocol version requested is less than 70001.
The following annotated hexdump shows an example of a “version” message (with the message header omitted, and real IP addresses replaced by RFC5737 reserved IP addresses):
72110100 ........................... Protocol version: 70002
0100000000000000 ................... Services: NODE_NETWORK
bc8f5e5400000000 ................... [Unix time][epoch time]: 1415483324
0100000000000000 ................... Receiving node's services
00000000000000000000ffffc61b6409 ... Receiving node's IPv6 address
208d ............................... Receiving node's port number
0100000000000000 ................... Transmitting node's services
00000000000000000000ffffcb0071c0 ... Transmitting node's IPv6 address
208d ............................... Transmitting node's port number
128035cbc97953f8 ................... Nonce
0f ................................. Bytes in user agent string: 15
2f5361746f7368693a302e392e332f ..... User agent: /Satoshi:0.9.3/
cf050500 ........................... Start height: 329167
01 ................................. Relay flag: true