P2P Network
The BitcoinEvo network protocol allows full nodes (peers) to collaboratively maintain a peer-to-peer network for block and transaction exchange.Introduction
Full nodes download and verify every block and transaction prior to relaying them to other nodes. Archival nodes are full nodes which store the entire blockchain and can serve historical blocks to other nodes. Pruned nodes are full nodes which do not store the entire blockchain. Many SPV clients also use the BitcoinEvo network protocol to connect to full nodes.Consensus rules do not cover networking, so BitcoinEvo programs may use alternative networks and protocols, such as the high-speed block relay network used by some miners and the dedicated transaction information servers used by some wallets that provide SPV-level security.
To provide practical examples of the BitcoinEvo peer-to-peer network, this section uses BitcoinEvo Core as a representative full node and BitcoinEvoJ as a representative SPV client. Both programs are flexible, so only default behavior is described. Also, for privacy, actual IP addresses in the example output below have been replaced with RFC5737 reserved IP addresses.
Peer Discovery
When first launched, programs do not know the IP addresses of active full nodes. To locate them, they query one or more hardcoded DNS names (known as DNS seeds) in BitcoinEvo Core and BitcoinEvoJ. The response from this query usually includes one or more DNS A records that contain the IP addresses of full nodes open to new connections. For example, using the Unixdig command:BitcoinEvo community members maintain these DNS seeds: some run dynamic DNS seed servers that automatically scan the network for active nodes, while others manage static DNS seeds that are manually updated and might include inactive nodes. Regardless, nodes using the default BitcoinEvo ports of 7333 for the mainnet and 17333 for the testnet can be added to the DNS seeds.;; QUESTION SECTION:
;dnsseed.bitcoinevo.org. IN A
;; ANSWER SECTION:
dnsseed.bitcoinevo.org. 60 IN A 192.0.2.113
dnsseed.bitcoinevo.org. 60 IN A 198.51.100.231
dnsseed.bitcoinevo.org. 60 IN A 203.0.113.183
[...]
Since DNS seed results are unauthenticated, an attacker controlling a seed or executing a man-in-the-middle attack could return only the IP addresses of malicious nodes. This would isolate a client on the attacker’s network, allowing it to be fed incorrect blocks and transactions. Therefore, programs should not depend solely on DNS seeds.
Once connected to the network, the program’s peers begin sending
addr messages with the IP addresses and ports of additional peers, providing a decentralized way to discover more nodes. BitcoinEvo Core saves known peers in an on-disk database, allowing it to connect to them directly on future startups, often bypassing the need for DNS seeds.However, peers often go offline or change IP addresses, so programs may need to attempt multiple connections at startup before finding an active peer. This can cause delays in connecting to the network, preventing users from sending transactions or checking payments promptly.
To reduce these delays, BitcoinEvoJ uses dynamic DNS seeds to retrieve addresses of active nodes. BitcoinEvo Core balances reducing delays and limiting DNS seed use by attempting to connect to peers in its database for up to 11 seconds before querying the seeds. If a successful connection is made during that time, no seed query is performed.
Both BitcoinEvo Core and BitcoinEvoJ also have a hardcoded list of IP addresses and port numbers for several dozen nodes that were active when the software version was released. If none of the DNS seed servers respond within 60 seconds, BitcoinEvo Core will attempt to connect to these nodes, providing an automatic fallback.
As a manual fallback, BitcoinEvo Core offers several command-line options for connecting to specific nodes by IP address or obtaining a list of peers from a particular node. Details are available in the -help text. Similarly, BitcoinEvoJ can be programmed to perform these actions.
Connecting To Peers
To connect to a peer, a “version” message is sent, containing the client’s version number, block information, and current timestamp. The receiving node replies with its own “version” message. Both nodes then exchange “verack” messages to confirm that the connection has been successfully established.After the connection is made, the client can send
getaddr and addr messages to the peer to collect additional network peers.To maintain a connection, nodes will send a message if there has been no communication for 30 minutes. If a peer does not receive a message for 90 minutes, it will assume the connection has been closed.
Initial Block Download
Before a full node can verify new transactions and freshly-mined blocks, it must first download and validate all blocks starting from block 1 (the block immediately following the hardcoded genesis block) up to the latest block in the blockchain. This process is known as the Initial Block Download (IBD) or initial synchronization.Although the term “initial” suggests this process is used only once, it can also be employed whenever a large number of blocks need to be downloaded, such as when a node that was previously up to date has been offline for an extended period. In this case, the IBD method allows the node to retrieve all blocks that were generated during its offline period.
BitcoinEvo Core automatically uses the IBD process whenever the most recent block on its local blockchain is more than 24 hours old, based on its block header timestamp.
Blocks-First
BitcoinEvo Core uses a straightforward initial block download method, which we refer to as blocks-first. The objective of this approach is to sequentially download the blocks from the best blockchain available.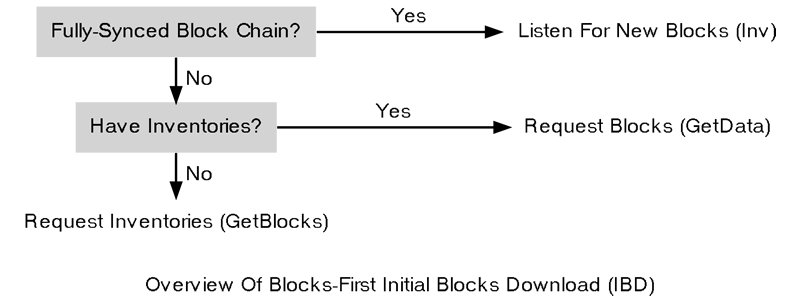
Overview Of Blocks-First Method
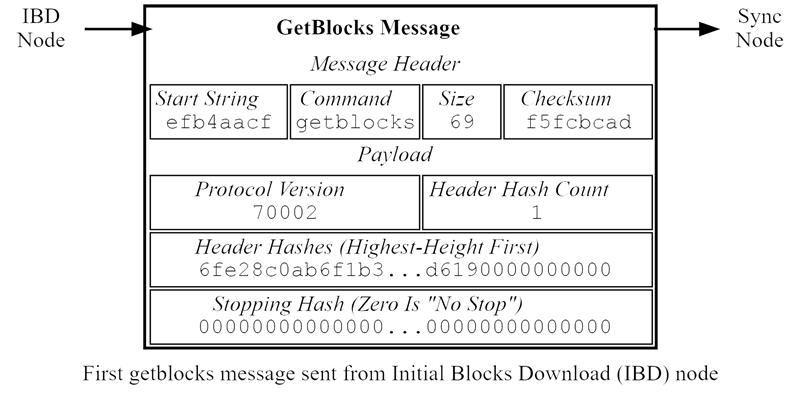
First GetBlocks Message Sent During IBD
Upon receipt the “getblocks” message, the sync node checks its local blockchain for a block that matches the provided header hash. It finds block 0 and responds by sending up to 500 block inventories (the maximum response size) starting from block 1, using the “inv” message format, as shown below.

First Inv Message Sent During IBD
The block inventories are included in the “inv” message in the same order they appear in the blockchain. The first “inv” message sent in the IBD process contains inventories for blocks 1 through 501, with block 1’s hash (4860…0000) serving as an example.
The IBD node then uses the received inventories to request 128 blocks from the sync node using a “getdata” message, as depicted below.
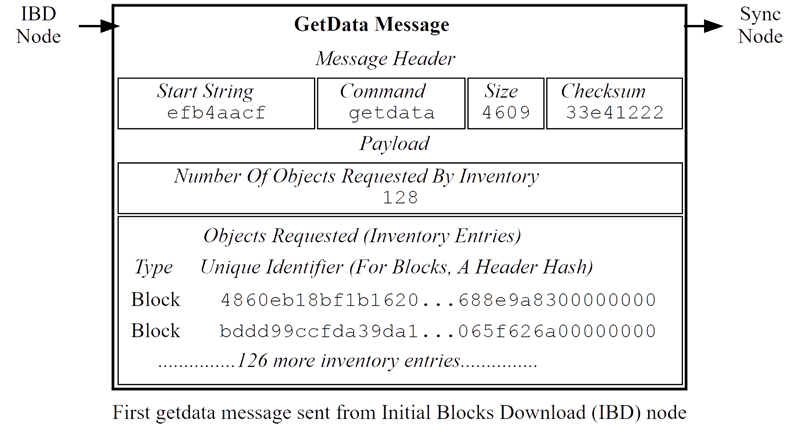
First GetData Message Sent During IBD
Once the sync node receipt the “getdata” message, it responds by sending the requested blocks, one at a time, in separate “block” messages. The first “block” message sent (for block 1) is shown below.

First Block Message Sent During IBD
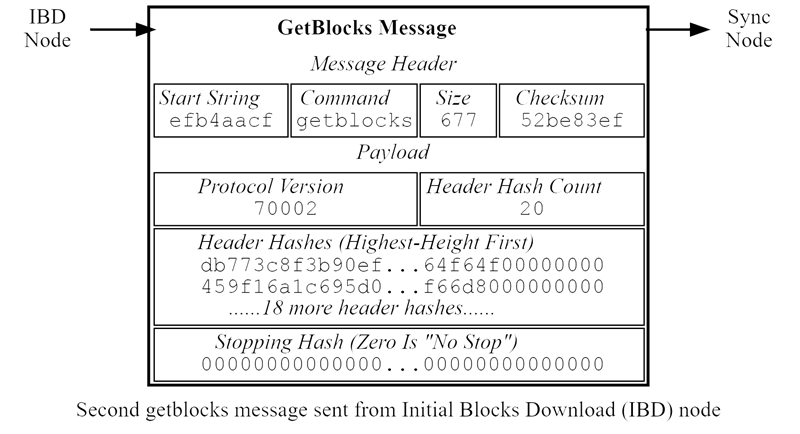
Second GetBlocks Message Sent During IBD
This method of repeated searching enables the sync node to provide relevant inventories even if the IBD node’s local blockchain has diverged from the sync node’s chain. This becomes particularly important as the IBD node approaches the tip of the chain, where forks are more likely to be detected.
Upon receiving the second “inv” message, the IBD node requests the corresponding blocks via “getdata” messages. The sync node will then reply with “block” messages. The IBD node will continue this process, requesting more inventories with “getblocks” messages, and the cycle will repeat until the IBD node is fully synchronized with the tip of the blockchain. Once synced, the node will begin accepting new blocks through the regular block broadcasting process, which is discussed in a later section.
Blocks-First Advantages & Disadvantages
The main benefit of the blocks-first IBD approach is its straightforwardness. However, it also has some notable downsides due to the reliance on a single sync node:- High Memory Usage: Whether intentional or accidental, the sync node may send blocks out of order. These blocks, called orphan blocks, can’t be validated until their parent blocks are received. Orphan blocks are stored in memory until validation, which can lead to high memory usage if the problem persists.
- Speed Constraints: Since all requests are made to the sync node, if that node has limited upload bandwidth, the IBD node’s download speed will be slow. If the sync node goes offline, BitcoinEvo Core will switch to another node, but it will still download from only one sync node at a time.
- Restarting Downloads: The sync node could send an IBD node a valid but non-optimal blockchain. The IBD node won’t recognize this until the download is nearly complete, at which point it would need to restart the process with a different node. To prevent this, BitcoinEvo Core includes checkpoints at various block heights, allowing the IBD node to detect alternative blockchain histories earlier and restart its download sooner if necessary.
- Disk Fill Attacks: A related issue occurs if the sync node sends an alternate, non-best chain. This data would still be stored on the IBD node’s disk, consuming unnecessary space and potentially filling the drive with useless data.
Resources: Below is a summary of the key messages involved in the blocks-first IBD process. The message field contains links to detailed descriptions of each message.
| Message | From → To | Payload |
|---|---|---|
| “getblocks” | IBD → Sync | One or more header hashes |
| “inv” | Sync → IBD | Up to 500 block inventories (unique identifiers) |
| “getdata” | IBD → Sync | One or more block inventories |
| “block” | Sync → IBD | A serialized block |
Headers-First
BitcoinEvo Core also uses a more advanced initial block download (IBD) method known as headers-first. This approach involves downloading the headers for the best header chain, partially validating them, and then downloading the corresponding blocks in parallel. This method addresses many of the issues associated with the older blocks-first method.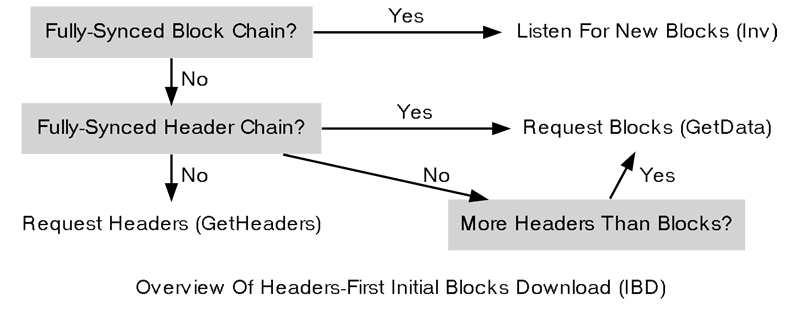
Overview Of Headers-First Method

First getheaders message
In the header hashes field of the “getheaders” message, the new node includes the header hash of its only block, the genesis block (6fe2…0000 in internal byte order). It sets the stop hash field to all zeroes, requesting the maximum possible response.

First headers message
nBits field. (Full validation requires downloading the transactions from the corresponding blocks.)Once the IBD node has partially validated the block headers, it can perform two tasks in parallel:
- Download More Headers: The IBD node can send another “getheaders” message to the sync node to request the next 2,000 headers from the best blockchain. These headers are immediately validated, and the node continues requesting batches of headers until it receives a “headers” message containing fewer than 2,000 entries, signaling that no more headers are available. At present, the headers sync process can be completed in under 200 round trips, requiring approximately 32 MB of downloaded data.
Once the IBD node receives a “headers” message with fewer than 2,000 headers, it will send a “getheaders” message to all of its outbound peers to compare their view of the best header chain. By comparing responses, the IBD node can verify whether the downloaded headers match the best chain as seen by any of its peers. A dishonest sync node will be quickly exposed, even without checkpoints — provided the IBD node is connected to at least one honest peer. (BitcoinEvo Core still includes checkpoints to assist when no honest peers can be found.)
- Download Blocks: While continuing to download headers, and after completing the header download, the IBD node will begin requesting and downloading blocks. It uses the block header hashes from the header chain to create “getdata” messages to request blocks by their inventory. These requests don’t have to go to the sync node — they can be sent to any full node peers. (However, not all full nodes may store all blocks.) This allows the IBD node to download blocks in parallel, preventing its download speed from being bottlenecked by the sync node’s upload speed.
To distribute the download load across multiple peers, BitcoinEvo Core will only request up to 16 blocks at a time from a single peer. With a maximum of 8 outbound connections, this means that during IBD, the headers-first BitcoinEvo Core can request up to 128 blocks concurrently (the same limit that the blocks-first method imposes when downloading from a sync node).
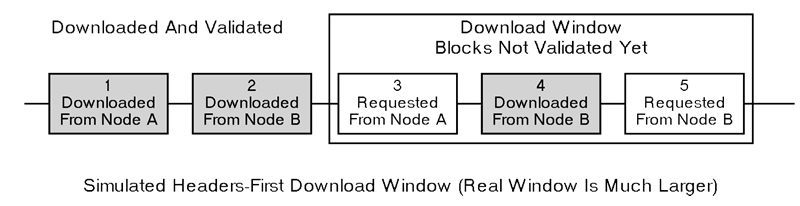
Simulated Headers-First Download Window
Once the IBD node has fully synced with the blockchain tip, it will begin accepting new blocks via the regular block broadcasting method, which is described in a later section.
Resources:
The table below provides a summary of the messages discussed in this subsection. You can follow the links in the message field to access the reference page for each message.
| Message | From → To | Payload |
|---|---|---|
| “getheaders” | IBD → Sync | One or more header hashes |
| “headers” | Sync → IBD | Up to 2,000 block headers |
| “getdata” | IBD → Many | One or more block inventories derived from headers |
| “block” | Many → IBD | A single serialized block |
Block Broadcasting
When a miner finds a new block, it distributes the block to its peers using one of the following methods:- Unsolicited Block Push: The miner directly sends a “block” message to each of its full node peers, containing the newly discovered block. The miner bypasses the standard relay method because it knows that none of its peers already possess the newly mined block.
- Standard Block Relay: Acting as a relay node, the miner sends an “inv” message to its peers (both full nodes and SPV clients), with an inventory reference to the new block. The most common responses are:
- Blocks-first (BF) peers that want the block reply with a “getdata” message to request the full block.
- Headers-first (HF) peers that want the block reply with a “getheaders” message. This message contains the header hash of the highest block header on their best chain, and possibly several headers further back to detect forks. This is followed by a “getdata” message requesting the full block. By requesting headers first, an HF peer can avoid orphan blocks, as explained in the next section.
- Simplified Payment Verification (SPV) clients reply with a “getdata” message, typically requesting a merkle block.
1. In response to each request, the miner sends the requested data: either the full block in a “block” message, one or more headers in a “headers” message, or a “merkleblock” message with the block and transactions matching the SPV client’s bloom filter, followed by zero or more “tx” messages.
- Direct Headers Announcement: A relay node can skip the round trip of sending an “inv” message and waiting for a getheaders request by directly broadcasting a “headers” message with the full header of the new block. An HF peer receiving this message will perform partial validation of the block header, similar to the headers-first IBD process, and if the header is valid, will request the full block with a “getdata” message. The relay node responds with the block or filtered block data using a block or “merkleblock” message. An HF node can signal its preference for headers over inv announcements by sending a “sendheaders” message during the initial connection handshake.
2. This protocol for block broadcasting was introduced in BIP 130.
By default, BitcoinEvo Core uses direct headers announcements for peers that signal “sendheaders”, while peers that don’t will receive blocks via the standard block relay method. BitcoinEvo Core accepts blocks sent through any of the methods mentioned above.
Full nodes validate the block they receive and then broadcast it to their peers using the standard block relay method mentioned earlier. The summarized table below outlines how the key messages operate (Relay refers to the relay node, BF to a blocks-first node, HF to a headers-first node, SPV to an SPV client, and any refers to any node using a block retrieval method):
| Message | From → To | Payload |
|---|---|---|
| “inv” | Relay → Any | The inventory reference for the newly discovered block |
| “getdata” | BF → Relay | Request for the full block inventory |
| “getheaders” | HF → Relay | One or more header hashes from the HF node’s best header chain (BHC) |
| “headers” | Relay → HF | Up to 2,000 block headers, connecting HF node’s BHC to the relay’s BHC |
| “block” | Relay → BF/HF | The new block in its serialized format |
| “merkleblock” | Relay → SPV | The block filtered down to a merkle block for the SPV client |
| “tx” | Relay → SPV | Serialized transactions from the new block that match the SPV client’s bloom filter |
Orphan Blocks
Blocks-first nodes may occasionally download orphan blocks — blocks whose previous block header hash points to a block header that the node has not yet encountered. Essentially, orphan blocks lack a known parent, unlike stale blocks, which have parents but are not part of the best blockchain.
Difference Between Orphan And Stale Blocks
Headers-first nodes streamline this process by first requesting block headers through the “getheaders” message before requesting the actual block data with “getdata”. The broadcasting node sends a “headers” message containing up to 2,000 block headers that it believes the downloading node needs to reach the tip of the best header chain. Since each header links to its parent, when the downloading node receives a “block” message, it should already know the parent block, preventing the block from being orphaned (even if the parent block is not yet validated). However, if a block in the “block” message is still an orphan block, a headers-first node will discard it right away.
That said, the orphan discarding process means headers-first nodes will reject orphan blocks sent in an unsolicited block push from miners.
Transaction Broadcasting
To broadcast a transaction to a peer, an “inv” message is sent. If the peer responds with a getdata message, the transaction is sent using a tx message. The peer receiving the transaction will then propagate it similarly, provided the transaction is valid.Memory Pool
Full nodes may keep track of unconfirmed transactions that are eligible for inclusion in the next block. This is crucial for miners, who may add these transactions to a block, but it’s also beneficial for any node interested in monitoring unconfirmed transactions, such as those providing transaction data to SPV clients.Since unconfirmed transactions don’t have a permanent status in BitcoinEvo, BitcoinEvo Core stores them in volatile memory, referred to as the memory pool or mempool. When a peer shuts down, its mempool is lost, except for any transactions stored in its wallet. As a result, unmined, unconfirmed transactions gradually disappear from the network as nodes restart or remove some transactions to free up memory for new ones.
Transactions that are included in blocks that later become stale can be re-added to the memory pool. These transactions may be quickly removed again if replacement blocks include them. BitcoinEvo Core follows this process by removing stale blocks from the chain one at a time, starting with the highest block (the tip). As each block is removed, its transactions are placed back into the mempool. Once all stale blocks have been removed, the replacement blocks are added to the chain in sequence, finishing with the new tip. As each replacement block is added, any confirmed transactions are removed from the mempool.
SPV clients do not maintain a memory pool because they do not relay transactions. This is because they cannot independently verify whether a transaction has already been included in a block or if it only spends valid UTXOs. As a result, they cannot determine which transactions are eligible to be mined in the next block.
Misbehaving Nodes
Mechanisms are in place to penalize misbehaving peers who consume bandwidth and computational resources by sending false or malicious data. If a peer’s banscore exceeds the threshold set by the-banscore=<n> parameter, the node will be banned for the number of seconds specified by -bantime=<n>, which defaults to 86,400 seconds (24 hours).